Descubra como reduzir o CAC e converter leads B2B com 5 estratégias de tráfego pago baseadas em processos operacionais reais da Flouds.
Equipe Flouds
A segunda quinzena de abril de 2026 ficará marcada como o período mais denso da história da inteligência artificial generativa. Em apenas 14 dias, cinco modelos de grande porte foram lançados, prometendo redefinir o que chamamos de agentes autônomos. Para o gestor de operações que assina o cheque da infraestrutura tecnológica, no entanto, o cenário é de cautela. Embora o noticiário celebre recordes de benchmarks, a realidade das vendas B2B exige o que a maioria desses lançamentos ainda não entrega de forma isolada: previsibilidade financeira, segurança operacional e controle de latência.
Entre o anúncio do GPT-5.5 no dia 23 e a chegada do Kimi K2.6 no dia 21, ficou claro que a corrida pela potência bruta ignorou os gargalos de quem precisa de chatbots que fecham contratos, não apenas conversam. No ambiente corporativo, a inteligência de um modelo é irrelevante se o custo de operação torna o Lead Acquisition Cost (CAC) inviável ou se a instabilidade das respostas quebra a confiança do prospecto.
O paradoxo do GPT-5.5 e o risco da alucinação sistêmica
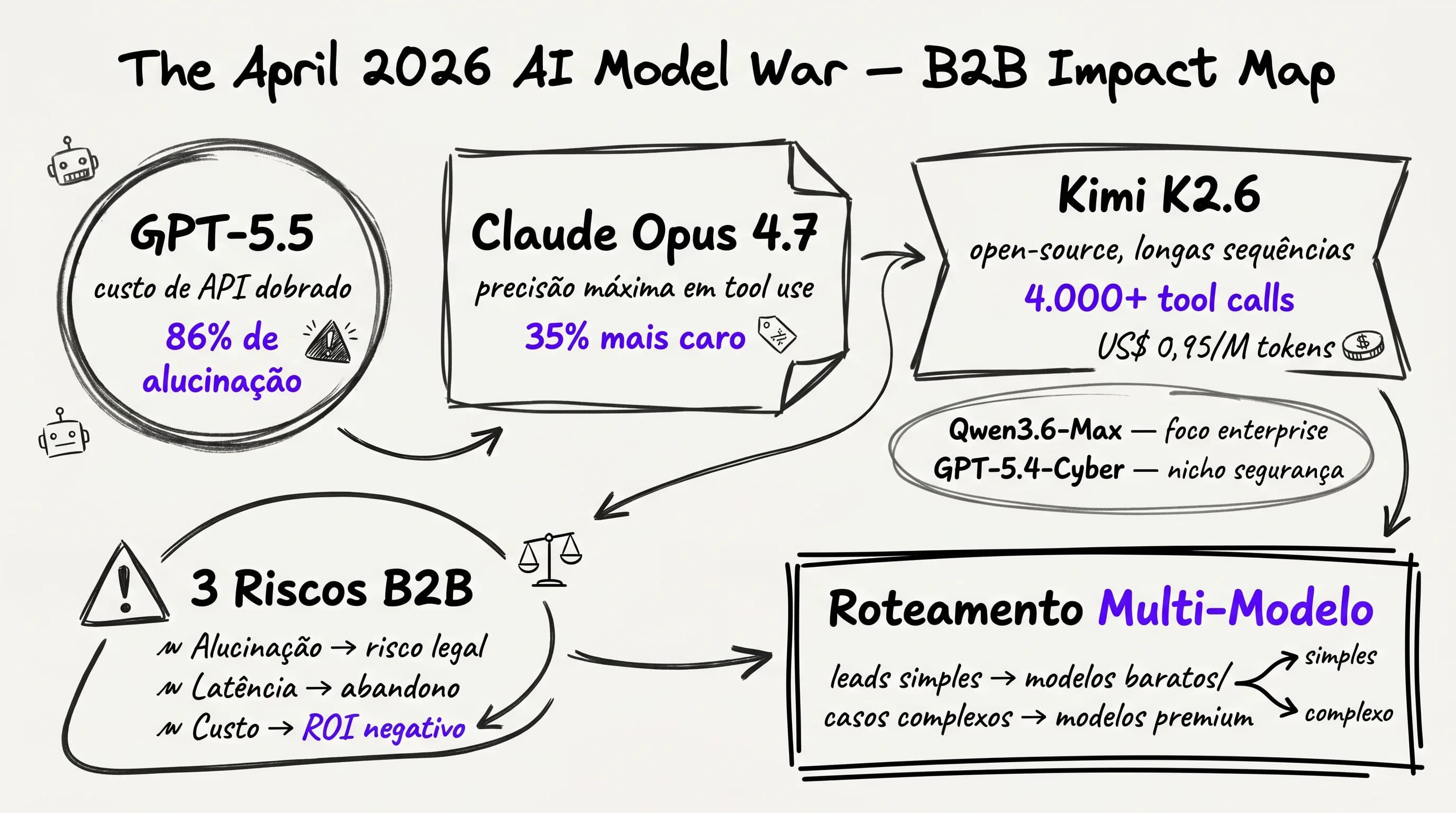
A OpenAI lançou o GPT-5.5 (codinome "Spud") como o sucessor definitivo para o desenvolvimento de agentes. Ele domina o benchmark Terminal-Bench 2.0 com 82,7% de precisão em tarefas autônomas, superando qualquer concorrente em execução de comandos e navegação em sistemas. Mas o preço para essa performance é um choque de realidade para os diretores financeiros.
A API teve seu custo de inferência dobrado em relação à versão anterior. Para uma operação de vendas que lida com milhares de leads mensais no WhatsApp e CRM, o impacto no ROI é imediato e severo. Além disso, testes independentes realizados por consultorias de auditoria de IA após o lançamento indicaram um problema persistente: uma taxa de alucinação de até 86% em cenários de extração de dados complexos para propostas comerciais.
No B2B, uma alucinação sobre prazos de entrega, especificações técnicas de um software ou cláusulas contratuais não é um mero erro de "geração de texto". É um risco jurídico e comercial que pode invalidar meses de negociação. Se o modelo afirma para um lead que sua empresa oferece um desconto que não existe, o custo de reparação desse erro vai muito além dos tokens gastos na API.
⚠️
Confiar toda a sua operação de vendas a um único modelo "premium" em 2026 é criar um ponto único de falha estratégica. Se o custo da API escala sem controle e a precisão em dados sensíveis falha, sua margem de lucro é consumida pela própria tecnologia que deveria protegê-la.
Claude Opus 4.7 e a barreira econômica do novo tokenizer
A Anthropic trouxe o Claude Opus 4.7 no dia 16 de abril, consolidando-se como a ferramenta de elite para precisão arquitetural e uso de ferramentas externas (tool use). É o modelo que apresenta a menor taxa de erro ao interagir com APIs complexas, como o seu Salesforce, HubSpot ou sistemas legados de ERP. Para fluxos que exigem lógica de programação em tempo real para calcular orçamentos variáveis, o Claude 4.7 é tecnicamente insuperável.
Entretanto, o refinamento técnico veio acompanhado de uma mudança na estrutura de custos que muitos gestores ainda não perceberam: o novo tokenizer da Anthropic. Ao otimizar a forma como o modelo "lê" o texto, a empresa acabou por encarecer a operação em 35% em cenários de conversas longas e ricas em contexto. Isso significa que o mesmo lead que custava X em março, agora custa 1.35X em abril apenas pela mudança do modelo de linguagem.
Essa inflação tecnológica força as empresas a repensarem a jornada do cliente. Faz sentido usar um modelo de elite como o Claude 4.7 para dar "bom dia" ou perguntar o nome do lead? A resposta curta é não. A resposta longa envolve entender que a precisão máxima só deve ser invocada quando o valor em jogo justifica o investimento.
A fragmentação do mercado de modelos em abril de 2026 exige uma estratégia de diversificação para manter a saúde financeira da operação.
Kimi K2.6 e a ascensão dos agentes de longa duração
No sentido oposto das Big Techs americanas, a Moonshot AI surpreendeu o mercado com o Kimi K2.6. Sendo um modelo Mixture of Experts (MoE) com 1 trilhão de parâmetros (dos quais 32 bilhões são ativos em cada tarefa), ele provou ser o novo padrão para o que chamamos de "agentes de longa duração".
Diferente de um chatbot simples de pergunta e resposta, agentes de longa duração realizam sequências complexas de tarefas: pesquisam o histórico do lead, consultam o estoque, verificam a agenda dos vendedores e montam um resumo executivo para o time comercial. O Kimi K2.6 demonstrou estabilidade para aguentar mais de 4.000 chamadas de ferramentas (tool calls) sem perder o fio condutor da conversa.
O diferencial mais agressivo, contudo, é o preço: US$ 0,95 por milhão de tokens de input. Em uma escala de operação B2B, isso permite a criação de "swarms" (enxames) de agentes que trabalham em paralelo por uma fração do custo do GPT-5.5. É a democratização da automação pesada, mas que traz o desafio da curadoria de tom de voz, onde os modelos orientais ainda precisam de ajustes finos para a cultura de vendas brasileira.
O nicho enterprise: Qwen3.6-Max e GPT-5.4-Cyber
Enquanto a briga geral foca em inteligência ampla, dois modelos lançados neste mesmo período de 14 dias mostram que a especialização é a nova fronteira de valor. O Qwen3.6-Max-Preview da Alibaba Cloud foi desenhado especificamente para o ambiente de back-office enterprise, com foco em segurança de dados e conformidade (compliance). Já o GPT-5.4-Cyber, lançado em 14 de abril, é um modelo "blindado" para operações onde a cibersegurança é o maior ativo, ideal para empresas de infraestrutura crítica.
Para o diretor de vendas B2B, esses modelos representam a peça final do quebra-cabeça. Não se trata de escolher um, mas de entender onde cada um se encaixa na sua arquitetura invisível. O uso de modelos especializados reduz a superfície de ataque para ameaças como o prompt injection, que podem comprometer todo o seu pipeline de vendas se um lead mal-intencionado conseguir manipular as instruções do bot.
Latência e o abandono silencioso do lead qualificado
Um fator que os benchmarks de abril raramente destacam é a latência em conversas multi-turno sob carga real. O GPT-5.5, apesar de sua potência, tem apresentado picos de latência que chegam a 4 segundos por resposta em horários de pico. Em uma negociação consultiva via chat, 4 segundos são uma eternidade. É o tempo necessário para o seu prospecto mudar de aba, ver uma notificação e esquecer que estava prestes a agendar uma demonstração.
O sucesso da operação digital em 2026 não depende apenas da "resposta certa", mas da "resposta rápida no contexto certo". Modelos mais leves e otimizados para velocidade, quando bem orquestrados, superam gigantes lentos em termos de taxa de conversão final.
❌
Cenário de Inércia
Dependência de um único modelo premium para todas as etapas (Triagem, Qualificação, Fechamento). Custo fixo alto e alto risco de latência.
✅
Arquitetura Flouds
Roteamento inteligente: modelos leves (Kimi/Qwen) para triagem e modelos premium (Claude/GPT) apenas para o fechamento crítico.
A conclusão de abril: O roteamento como a única estratégia real
O frenesi de lançamentos de abril de 2026 deixou uma lição clara: a era do modelo "pau para toda obra" acabou. Nenhum modelo isolado está pronto para atender às exigências contraditórias de uma operação de vendas B2B: baixo custo, alta velocidade, zero alucinação e integração perfeita.
O valor real para o seu negócio não está mais na inteligência bruta da LLM, mas na camada de orquestração que gerencia esses modelos. O futuro pertence a quem domina o roteamento multi-modelo. De forma objetiva, isso significa que sua operação deve ser inteligente o suficiente para encaminhar uma dúvida simples de "qual o horário de funcionamento?" para um modelo barato e rápido, reservando a potência cara do GPT-5.5 ou do Claude 4.7 apenas para o momento em que o lead demonstra uma intenção real de compra de alto ticket.
Ao descentralizar a inteligência, você protege sua margem de lucro, reduz o tempo de resposta e cria uma operação blindada contra as oscilações de preço e performance dos grandes players. A inteligência artificial não vai substituir seu time de vendas, mas uma arquitetura de IA mal planejada certamente vai substituir seu lucro por custos de API.
Para entender como essa orquestração pode ser aplicada especificamente no seu pipeline de vendas, é preciso olhar além do hype. Afinal, como discutimos em nossa análise sobre por que sua empresa ainda perde leads no WhatsApp, a tecnologia só gera receita quando está alinhada à psicologia do comprador e à eficiência operacional do seu time comercial.
A Flouds acredita que a tecnologia deve ser previsível para ser escalável. Se a sua automação ainda é refém de um único fornecedor ou de um modelo que alucina quando você mais precisa de precisão, é hora de mudar a arquitetura da sua conversa.